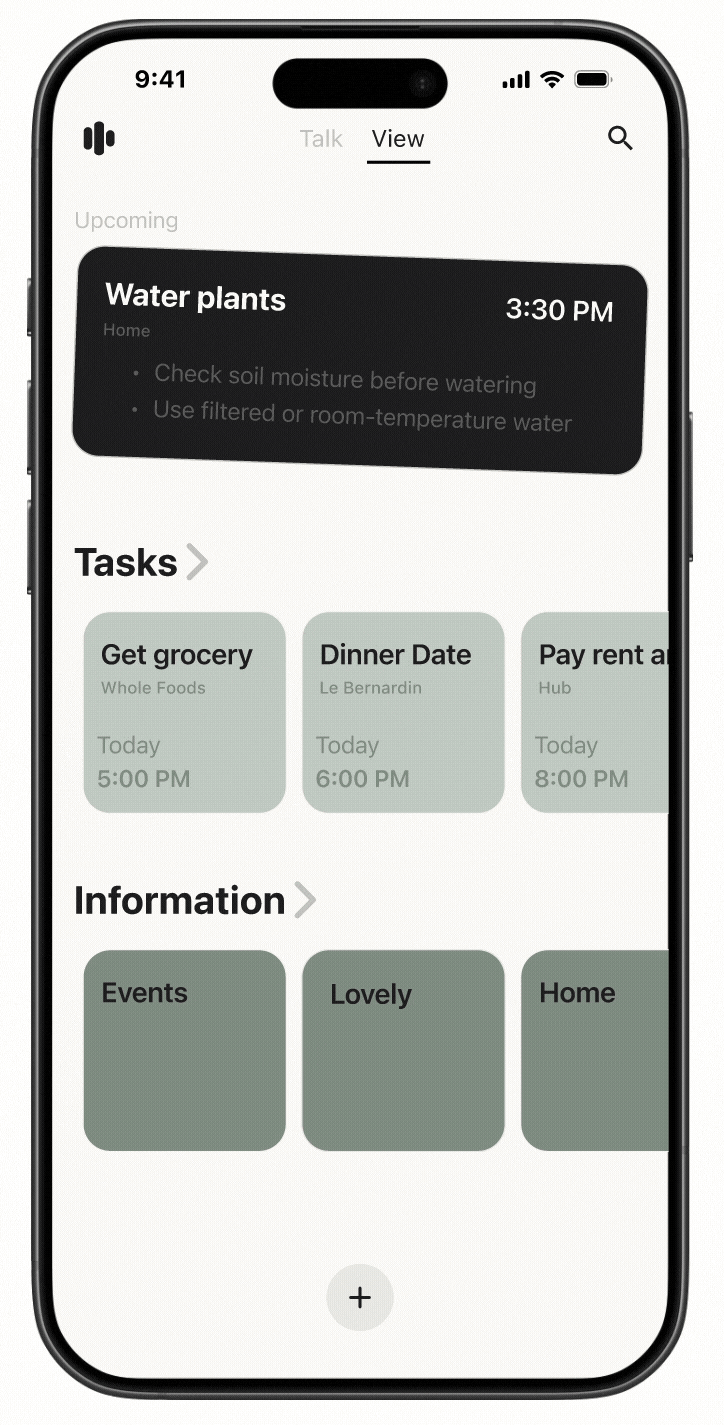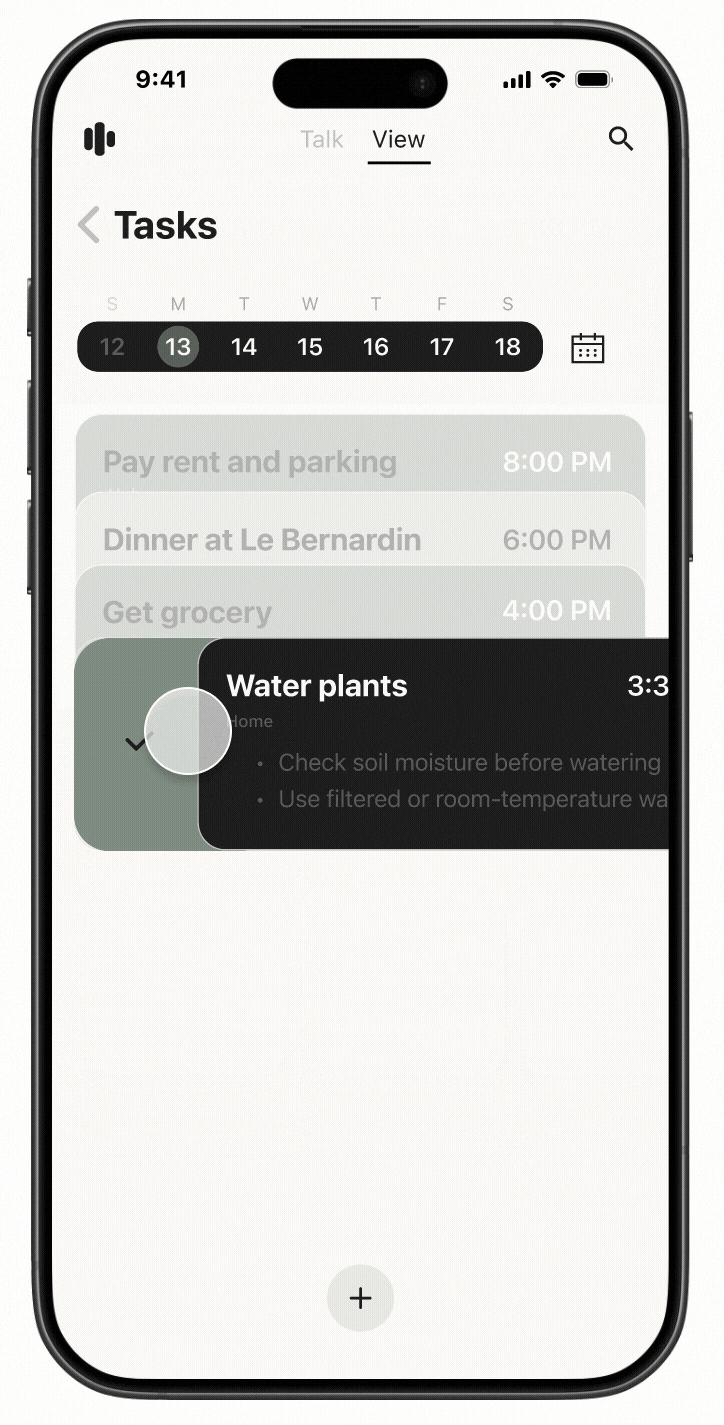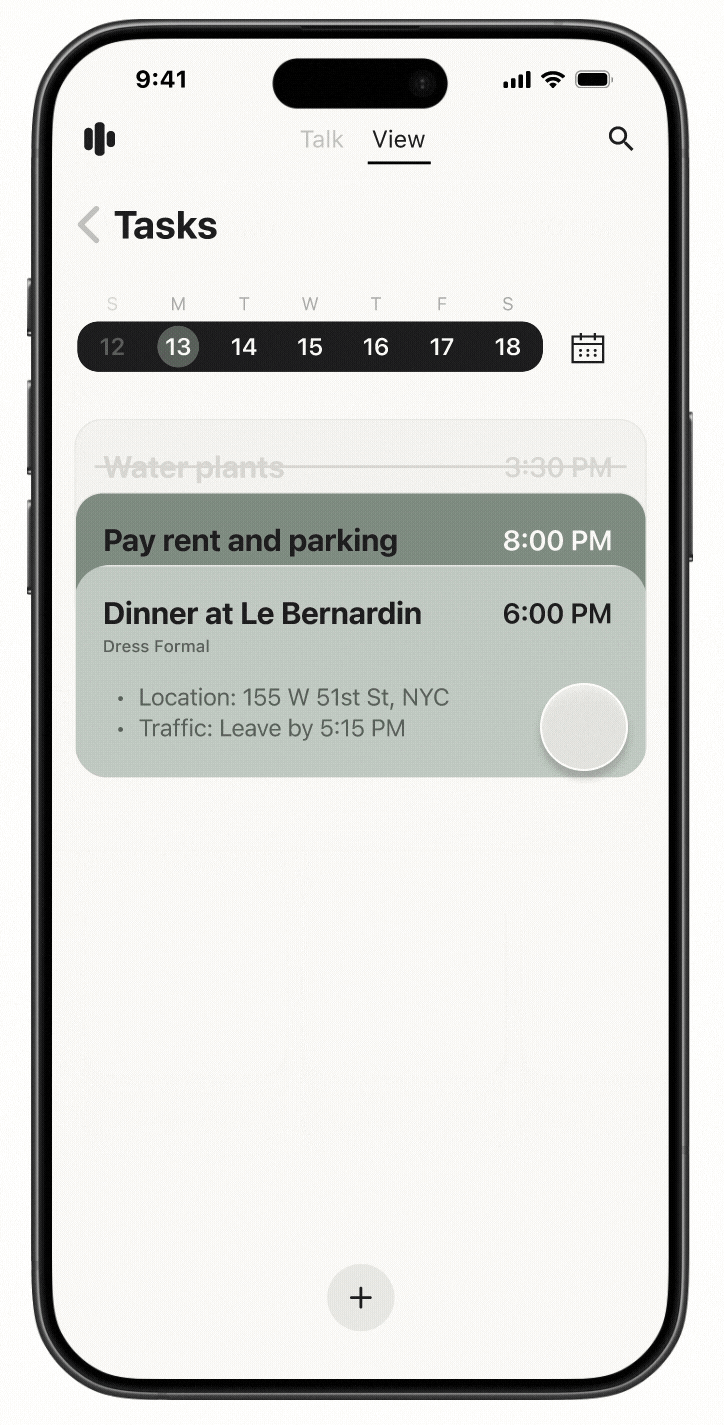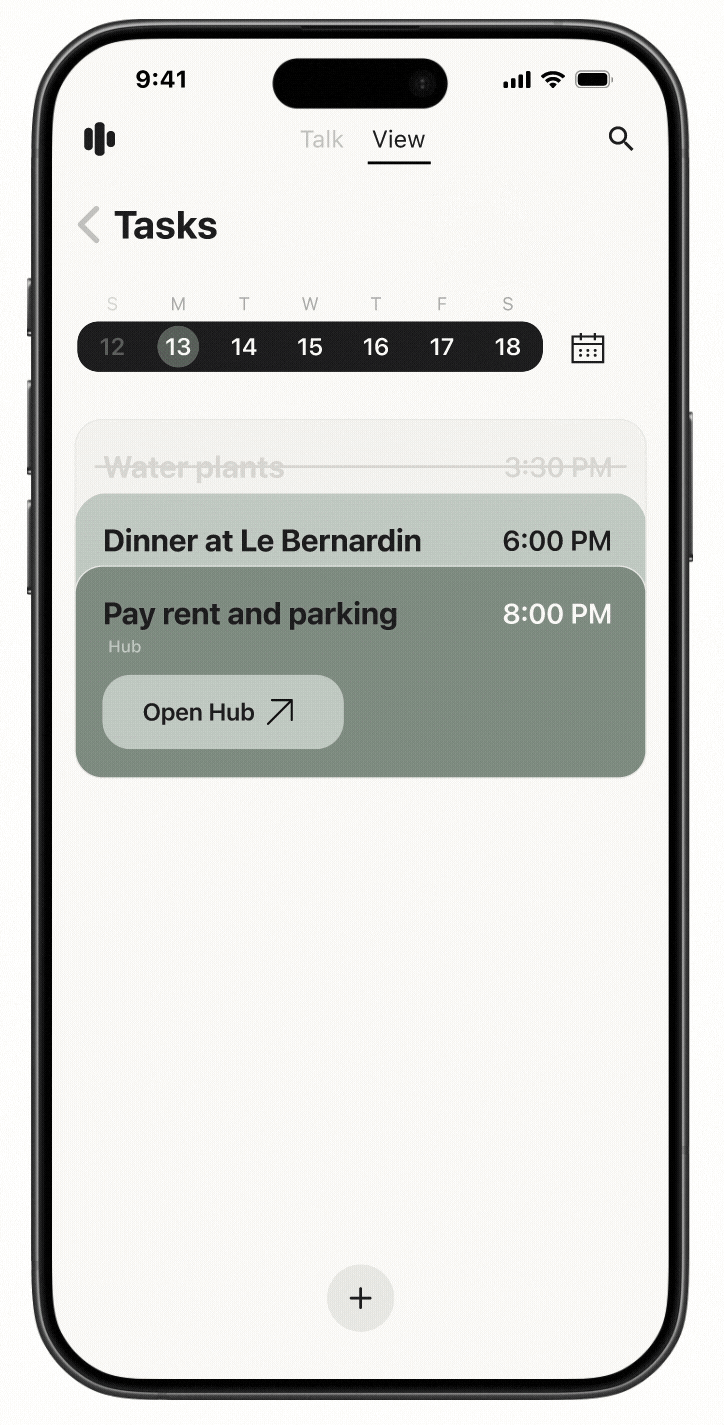
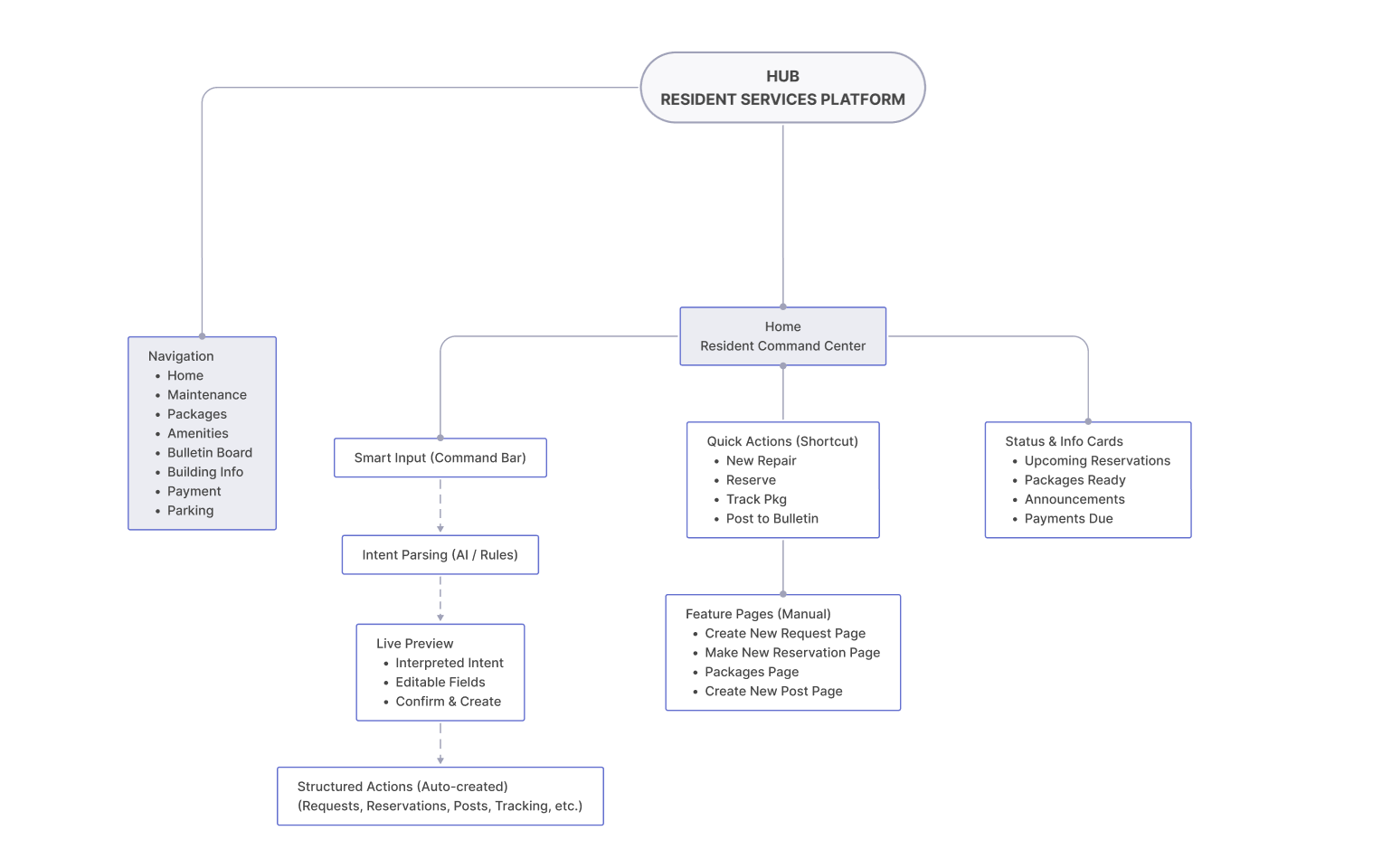
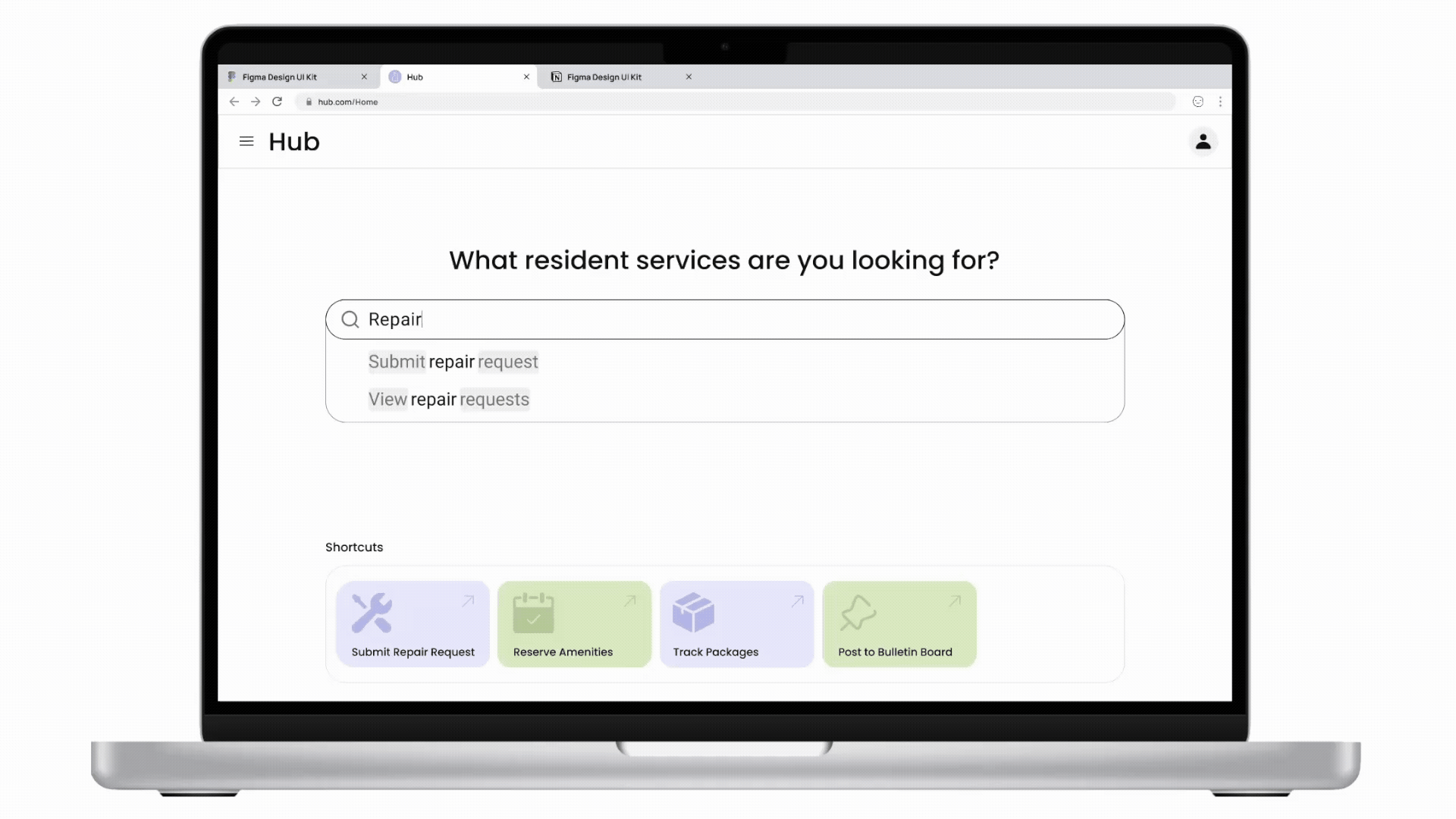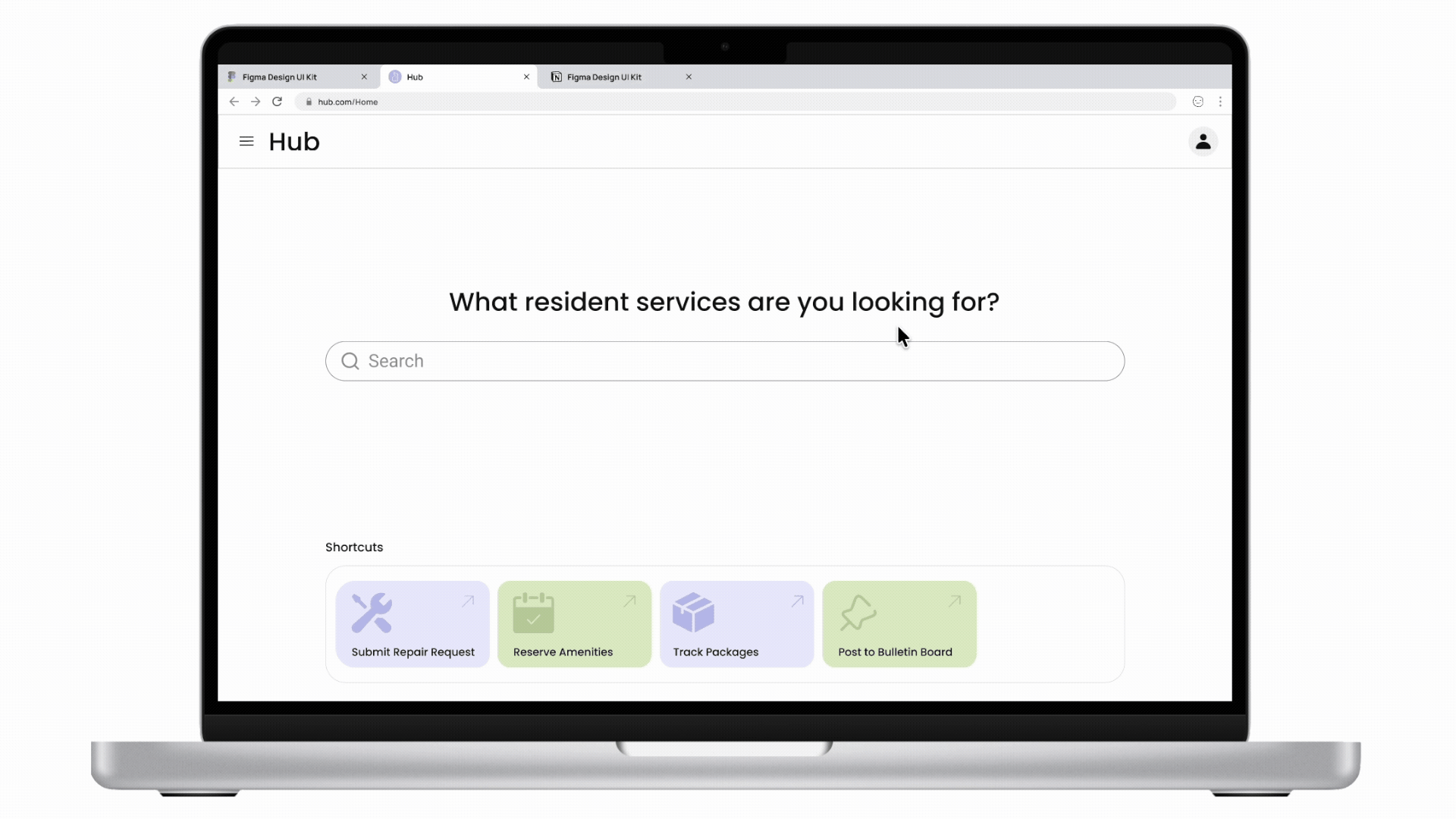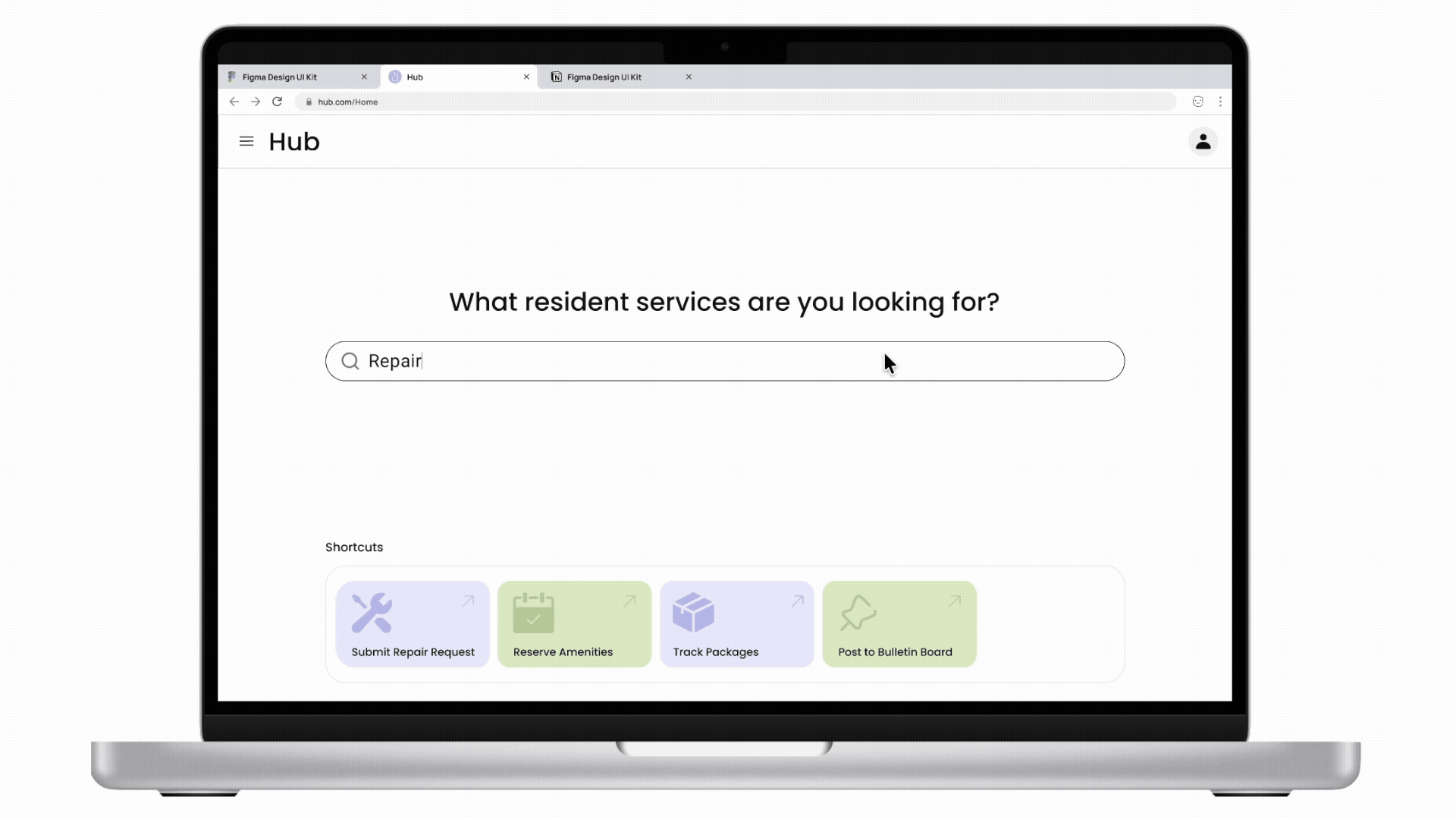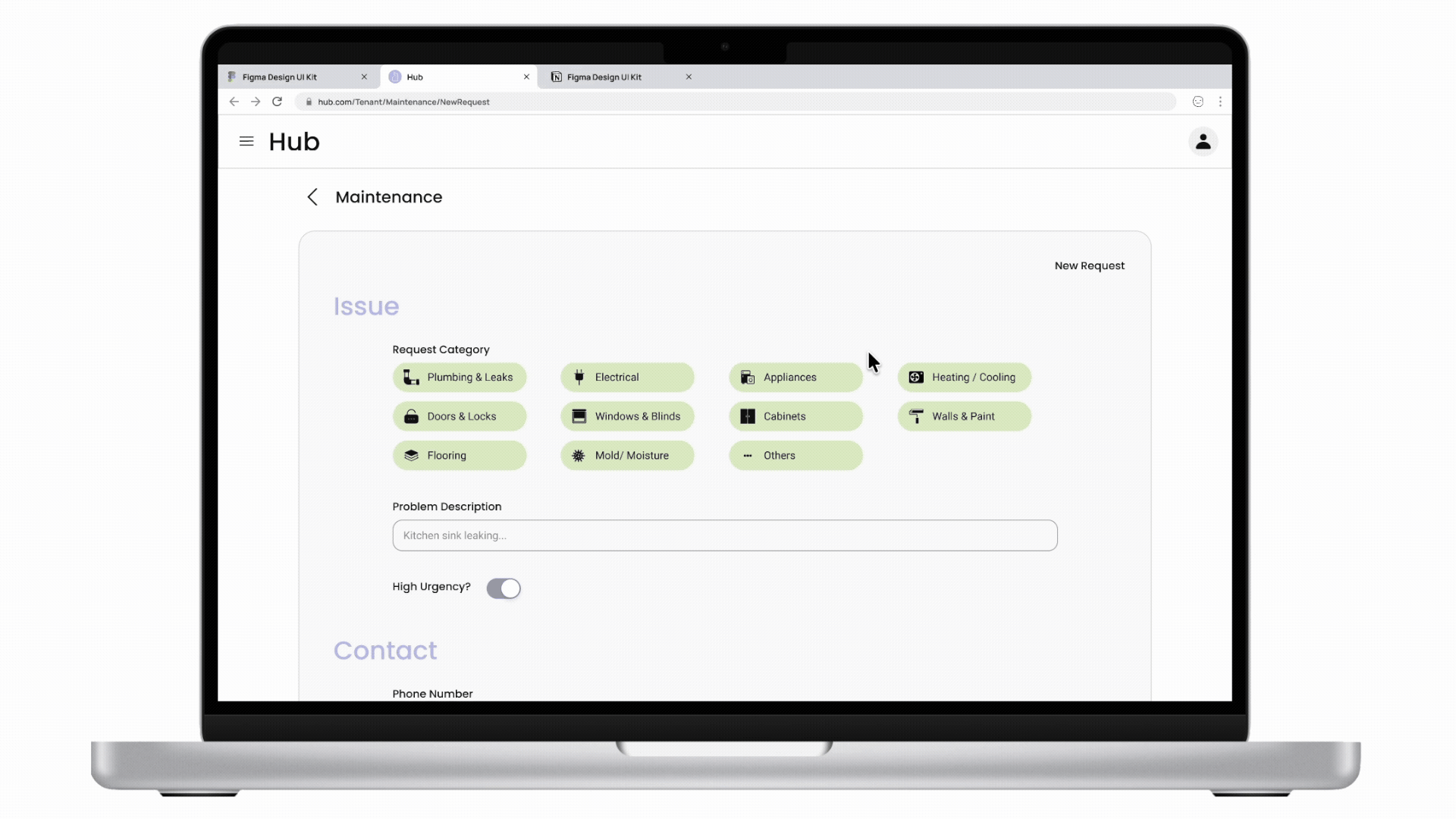
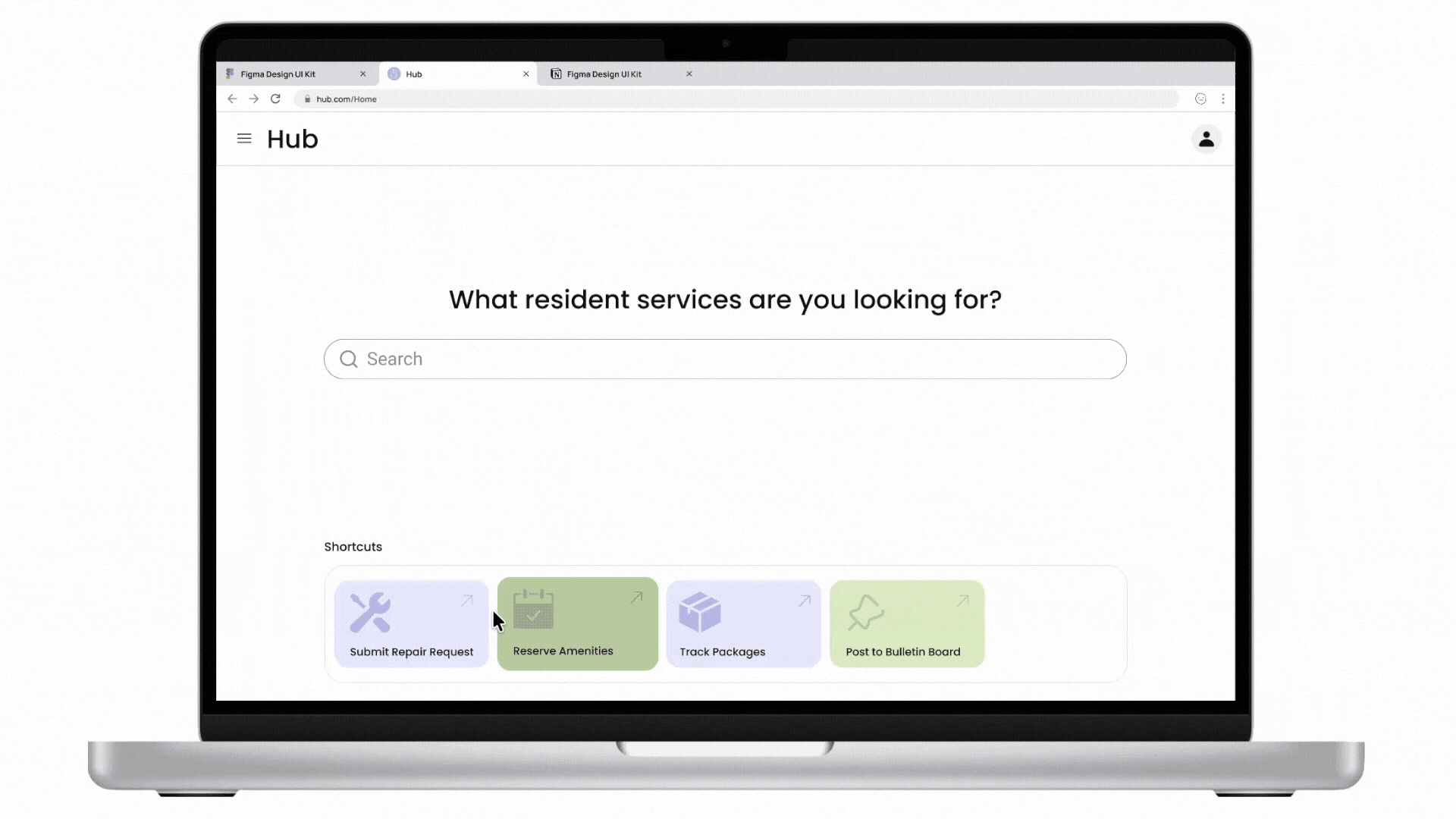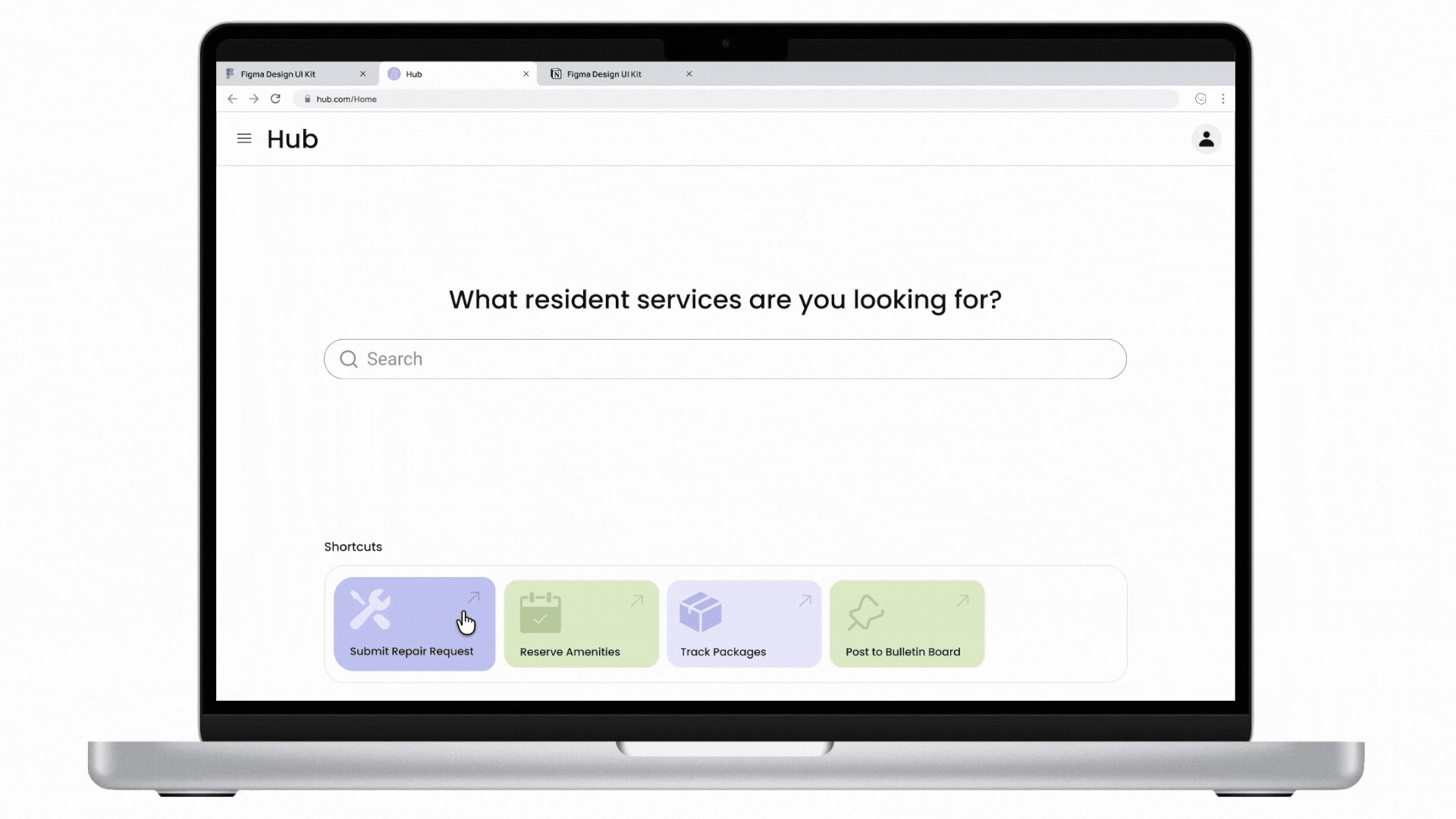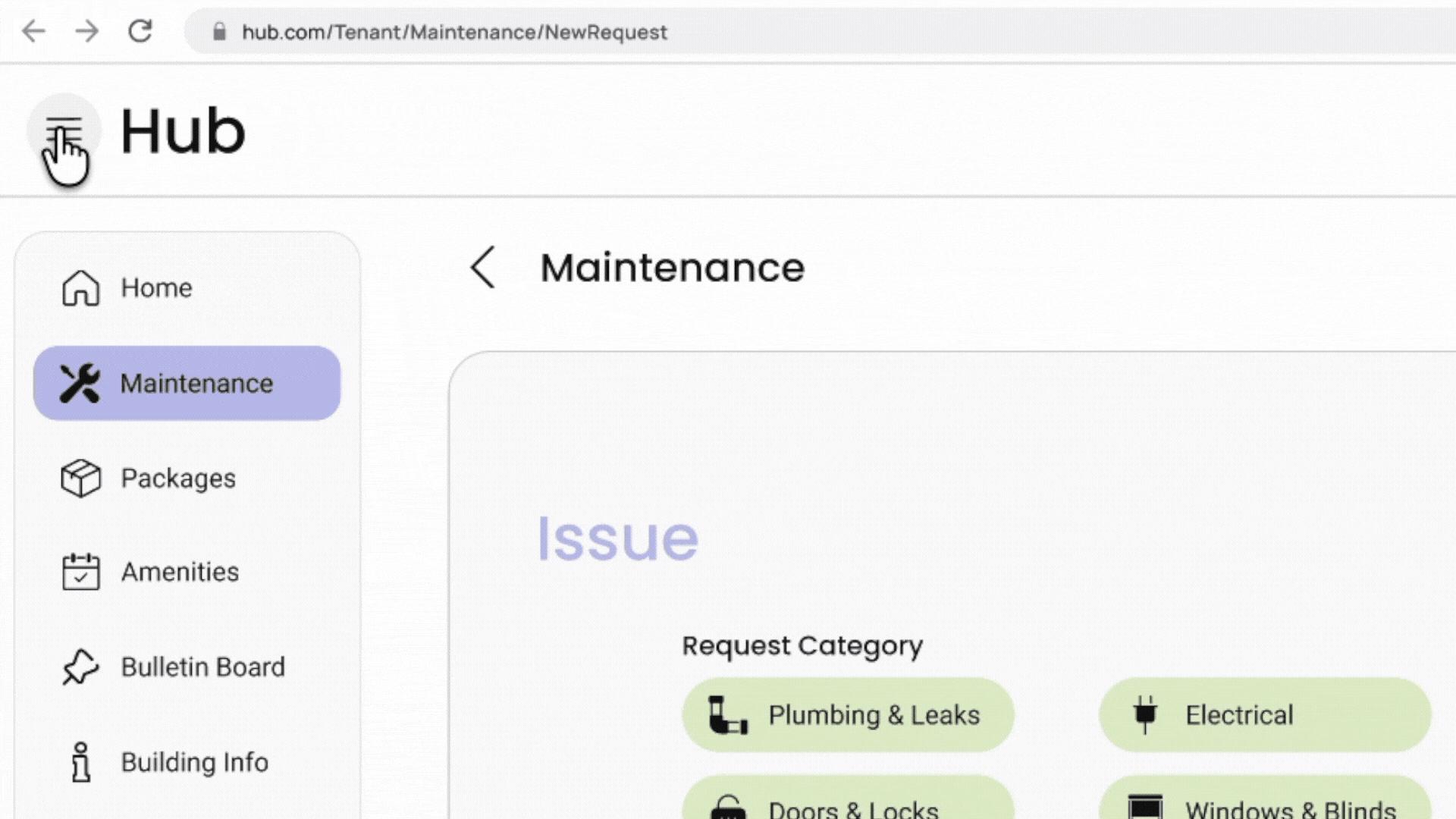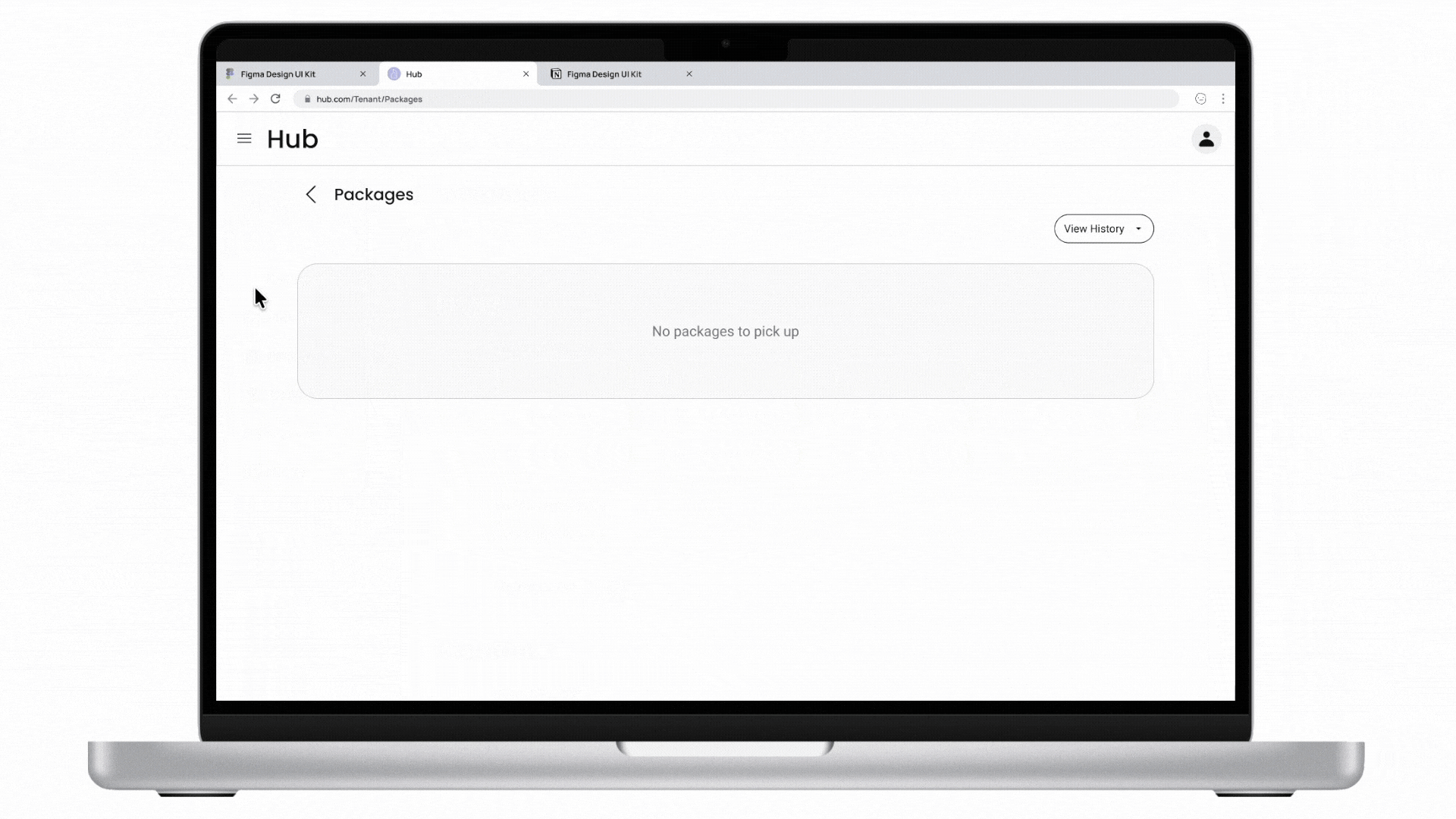
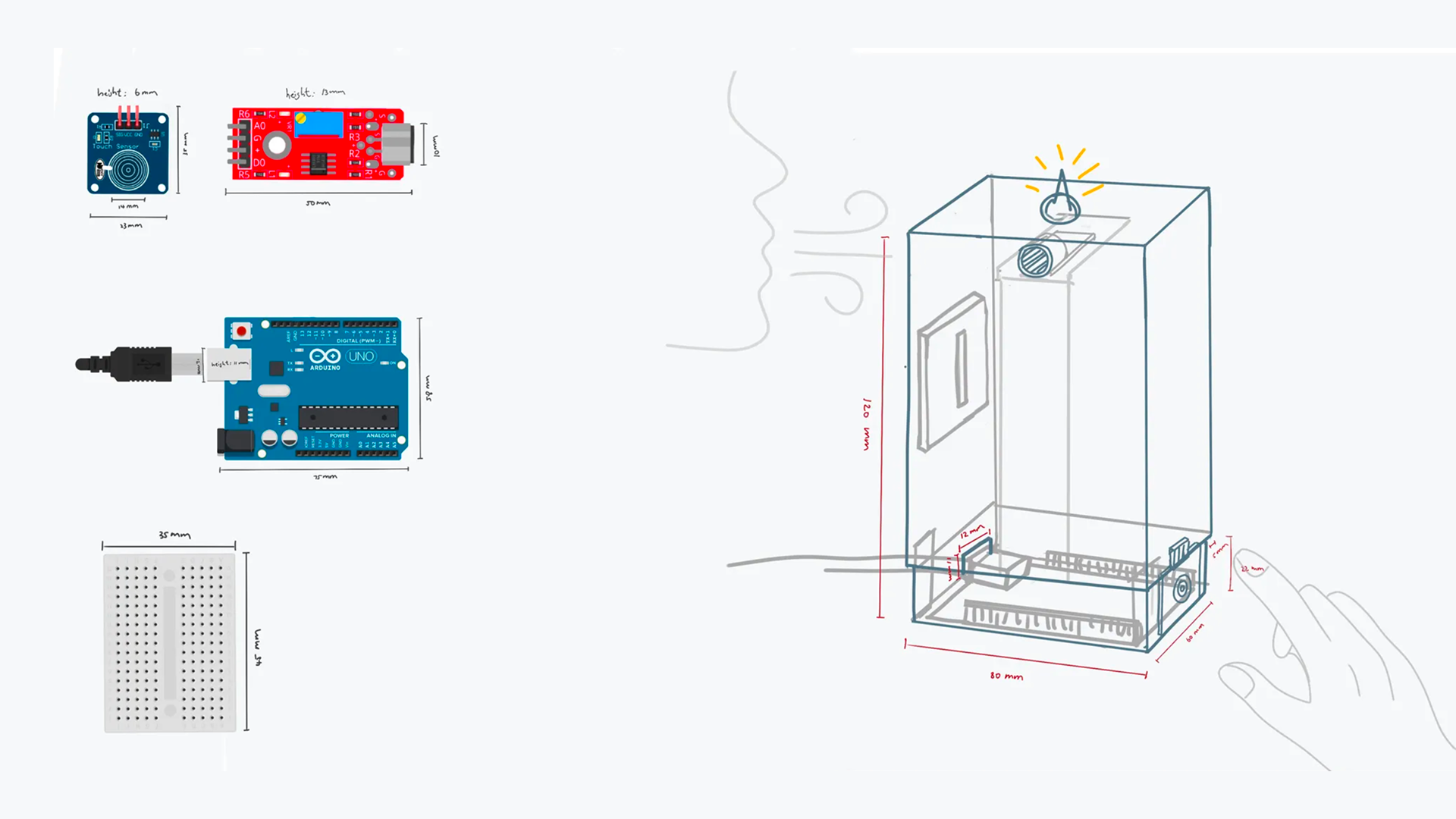
Cactus is a task and information management app designed to reduce cognitive overload through conversational AI and smart automation. The project is inspired by cognitive science studies and built upon extensive user experience research. I led user research, product definition, and interaction design, translating cognitive load theory into practical UX decisions across onboarding, task capture, prioritization, and AI-driven recommendations.


















.gif)






































.gif)


